SVG Model
YEAR
2023
ABOUT
Our team at Poly built a next-generation SVG model that enabled designers to generate vector assets from text, sketches, reference images, or even extrapolate full asset sets from a single style example.
At its core is a diffusion model conditioned on a vast array of signals, designed as a flexible, API-style system. We introduced novel contrastive learning methods for understanding asset sets, and advanced VLM-based approaches for structured SVG generation.
KEY INITIATIVES
Large scale data labeling projects, novel interaction patterns, actionable user studies
Problem Validation
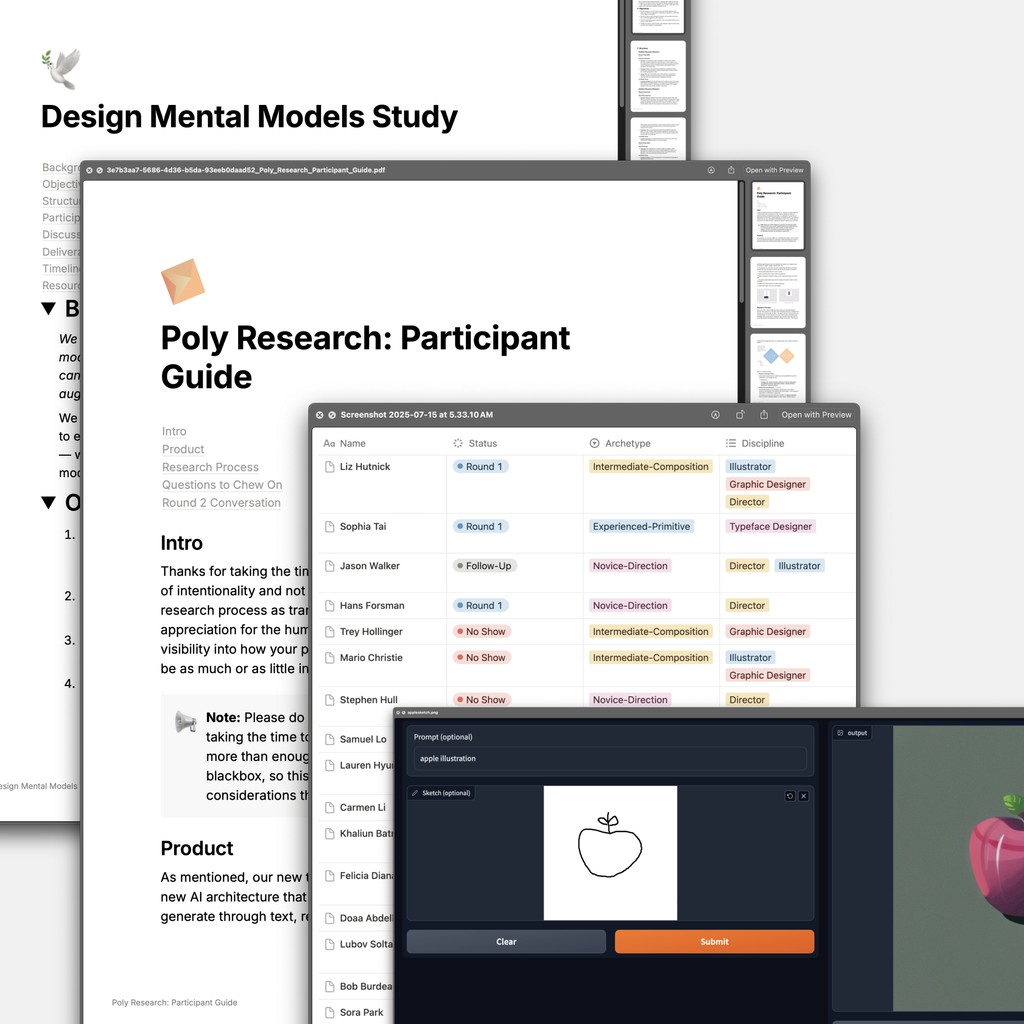
[DESIGN MENTAL MODELS STUDY]
I began by running a comprehensive user study to fully understand designers' mental models around vector assets and identify the most effective forms of conditioning our model we could offer.
I operated within a rapid validation loop to uncover the breadth of creative intents across different designer archetypes and roles, from spinning up Gradio demo environments for quick model prototypes, to a stream of UI demos.

[MODEL CONDITIONINGS]
Solution Validation
[CREATIVE INTENT EXERCISE]
With our conditionings defined, the next step was to run interactive sessions with users to collect ground-truth input/output examples for modeling and labeling. This included capturing live prompts, drawing mask inputs, and simulating other conditions to gather authentic data.
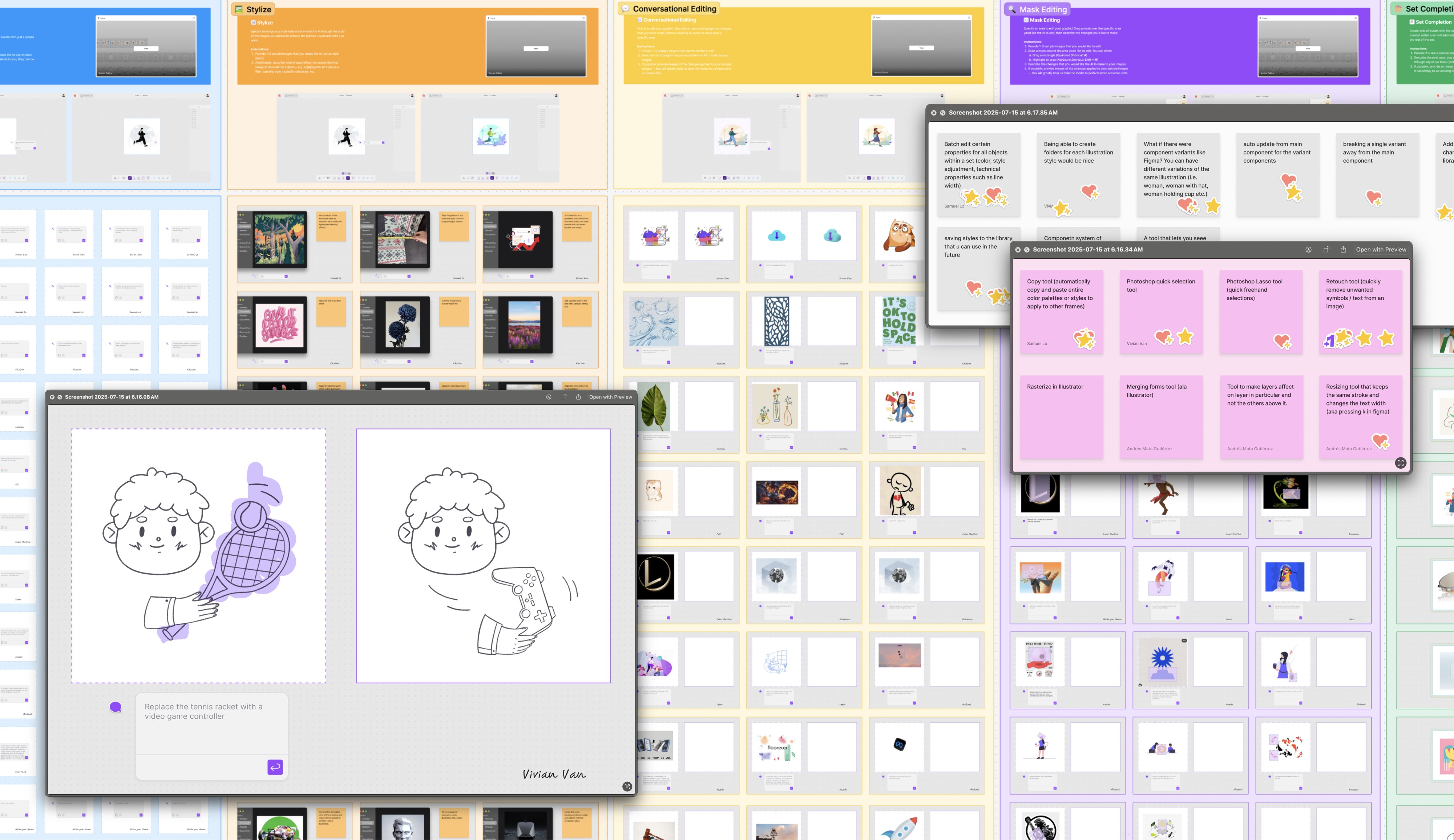
[INTERACTIVE PROTOTYPE]
This foundational work culminated in a fully interactive prototype that showcased the model’s potential. It was our sole demo at the time, used to help us raise an additional $4M (bringing total funding to $8M), which was necessary to build out a 128+ GPU cluster for training.
Beyond fundraising, the prototype also laid the groundwork for the end-to-end design of the creative platform itself.
Novel interaction patterns were discovered and implemented — particularly direct manipulation techniques allowing users to prompt and manipulate media directed by the cursor, rather than remaining limited by the traditional static text input mechanisms.
Data Labeling
[DATA COLLECTION SYSTEMS]
We built multiple workflows to collect different types of data based on our model conditionings. This included working with several data labeling firms, each trained on custom task guidelines and taught to use tools like Photoshop and Figma for labeling and review.
For several projects, we managed weekly volumes of 25k–35k labeled outputs, balancing speed with quality through constant iteration.

[SOURCING & EVALUATION FRAMEWORKS]
We had to source and label highly specific, real-world use cases — the kind of data that simply doesn’t exist in off-the-shelf datasets, especially for things like design sets or sketches. To address this, we not only collected unique human-labeled data, but also trained embedding models on our specialized datasets to generate high-quality synthetic data at scale.


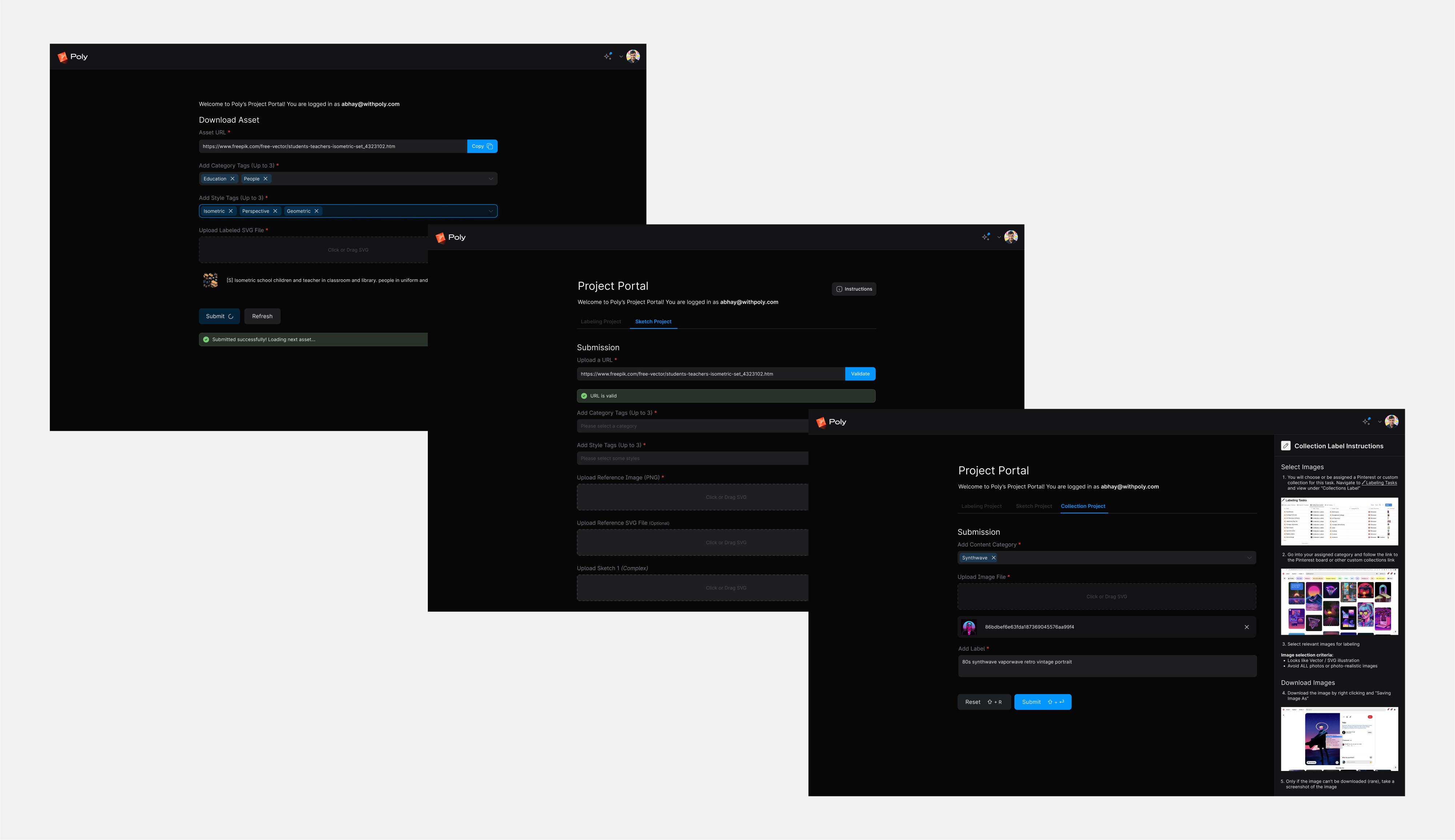
[SUBMISSION PLATFORM]
We also designed and built a custom data annotation and submission platform tailored to our workflows. It allowed labelers to submit links for us to scrape, apply tags and categories, upload their work, and access task-specific docs and instructions — all in one place.